Data Pipeline
Overview
This document describes the pipelines and triggers implemented for this project. A link to the backfill process is provided at the ned.
The end-to-end data batch processing pipeline consists of two pieces.
The first pipeline piece is created by using Github Pipeline and second piece is created by using Mage pipeline.
Github Pipelines
There are two Github pipeline jobs created for this project.
Fetch Data
This pipline is scheduled to run every hour on the dot. When it runs, it executes the weather data loader Python script. The script has a list of hard-coded office ids. For each office id, script retrieves a list of weather station ids and make request to retrieve current weather data from National Weather Service for each station id.
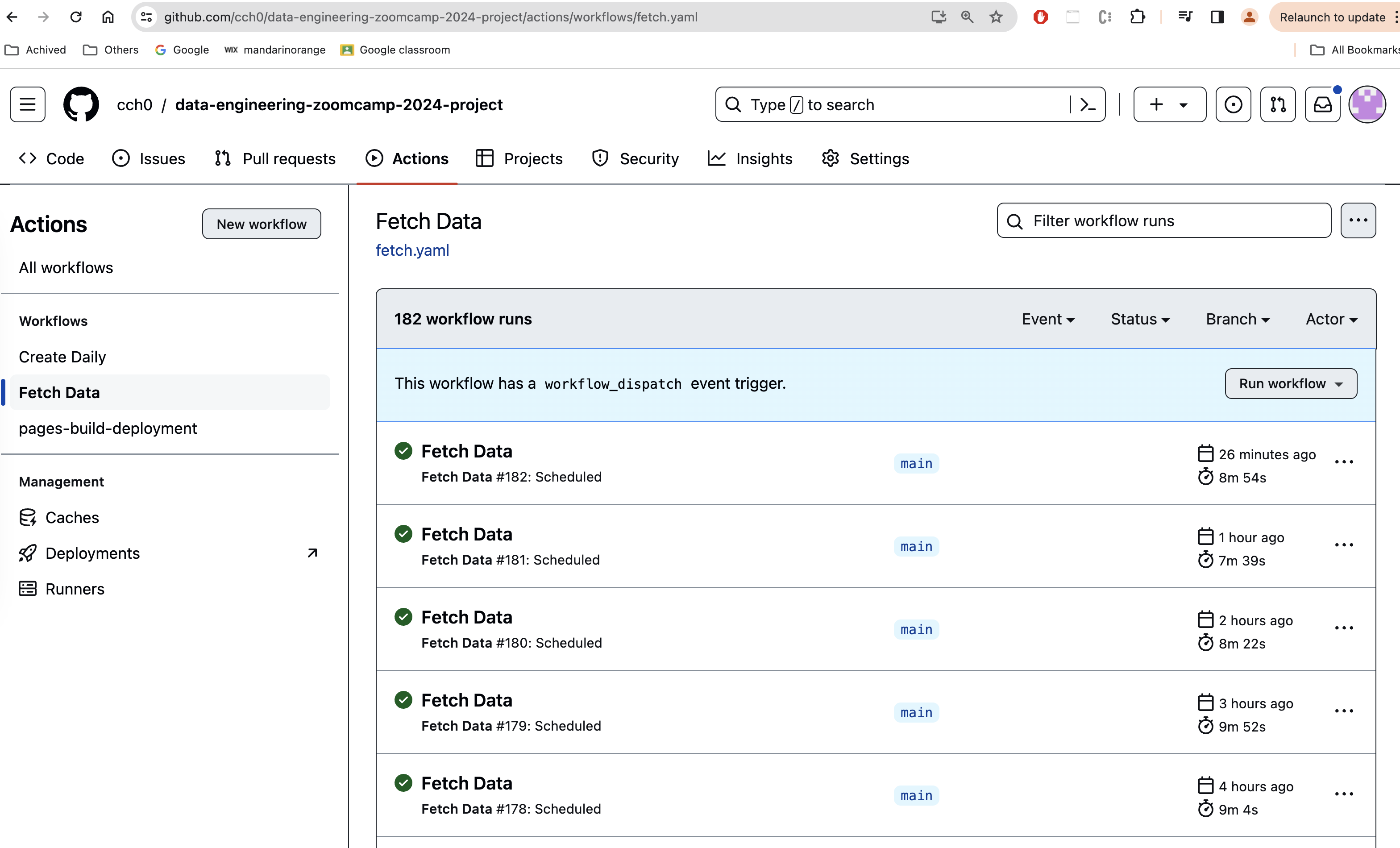
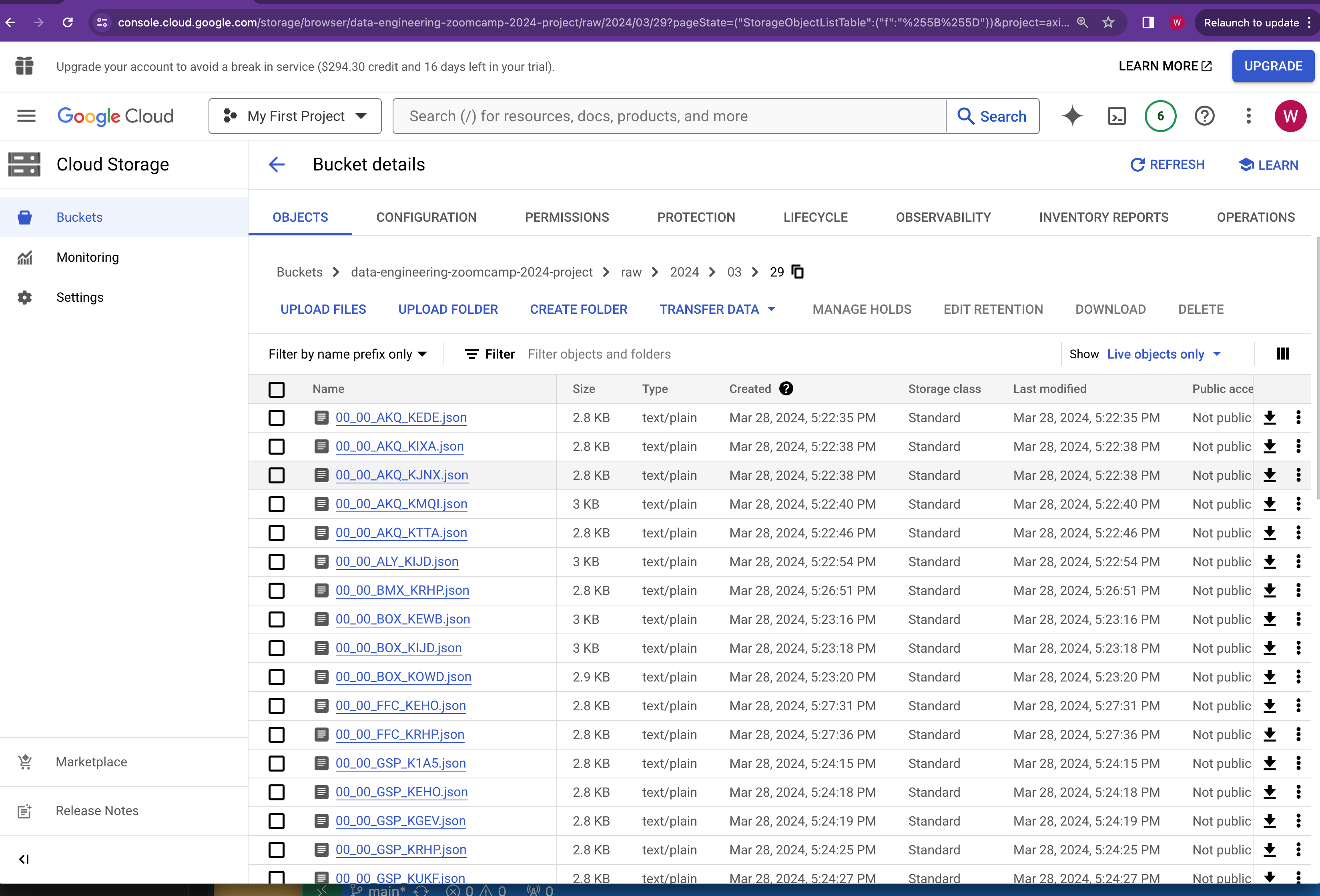
The fetched data will be finally stored as json file in Gloud Storage bucket named data-engineering-zoomcamp-2024-project and under the raw prefix indicating this is the raw data we collected.
The json file name is partitioned on year, month and day.
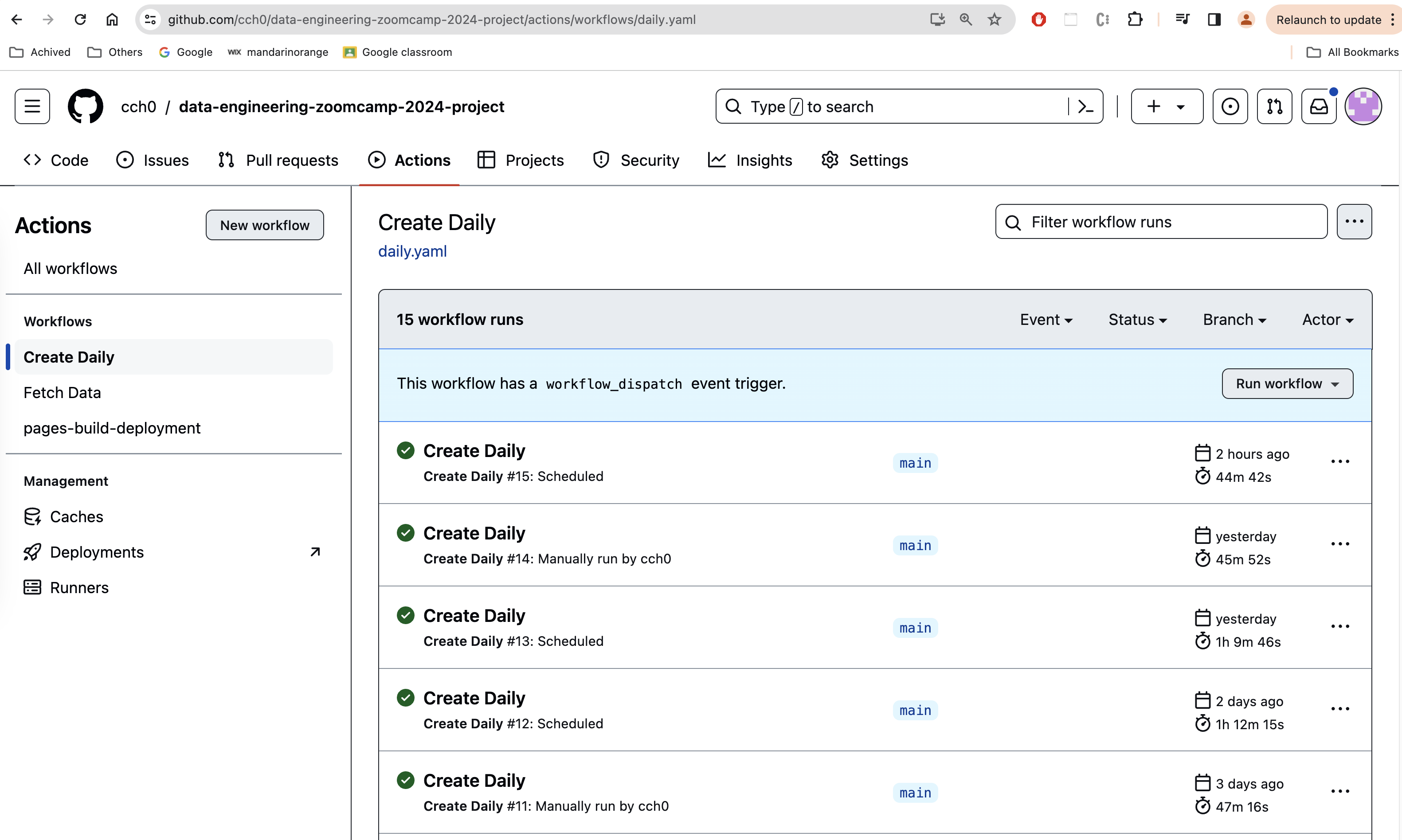
Create Daily
This pipline is scheduled to run every day 10 mins before midnight. When it runs, it execute the transform.py Python script. The script is fetching all the json files from the Cloud Storage bucket based on the provided execution date.
When pipeline is a scheduled job, the execution date is the current date. When pipeline is kicked off manually, user can enter a particular date as the execution date. This would be the backfill scenario.
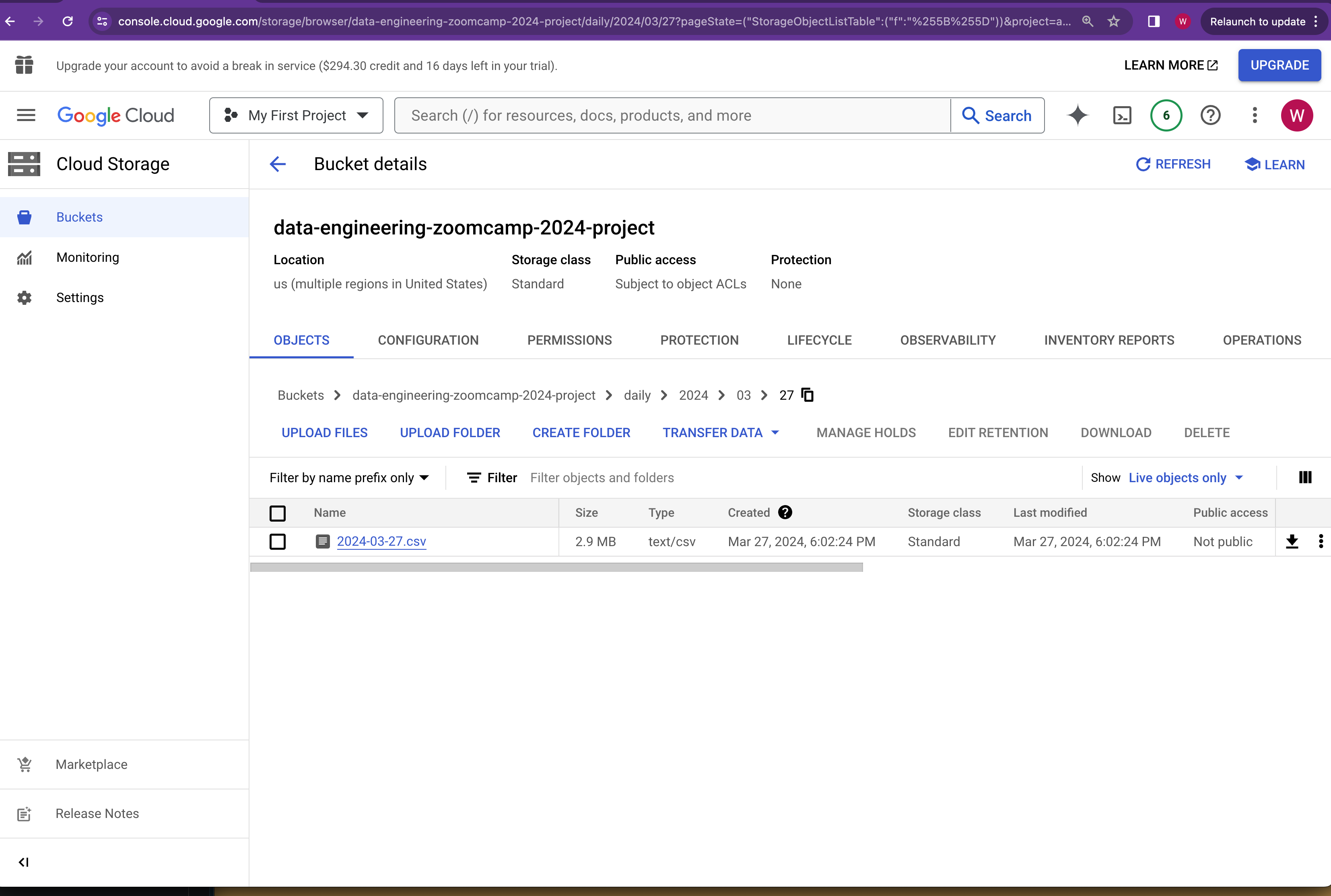
The downloaded json files will be aggregated together. A transformation process is applied to extract interesting fields and produces a new output object in csv format.
For each execution date, one single csv file will be created and uploaded back to Cloud Storage bucket under the daily prefix and paritioned by year, month and day.
Mage Pipelines
Mage pipeline consists of total 5 blocks
1. ingest from cloud storage Data Loader
This data loader loads daily csv file from Cloud Storage bucket for the execution time. Execution time is provided by Mage and can be overrided during the backfill process.
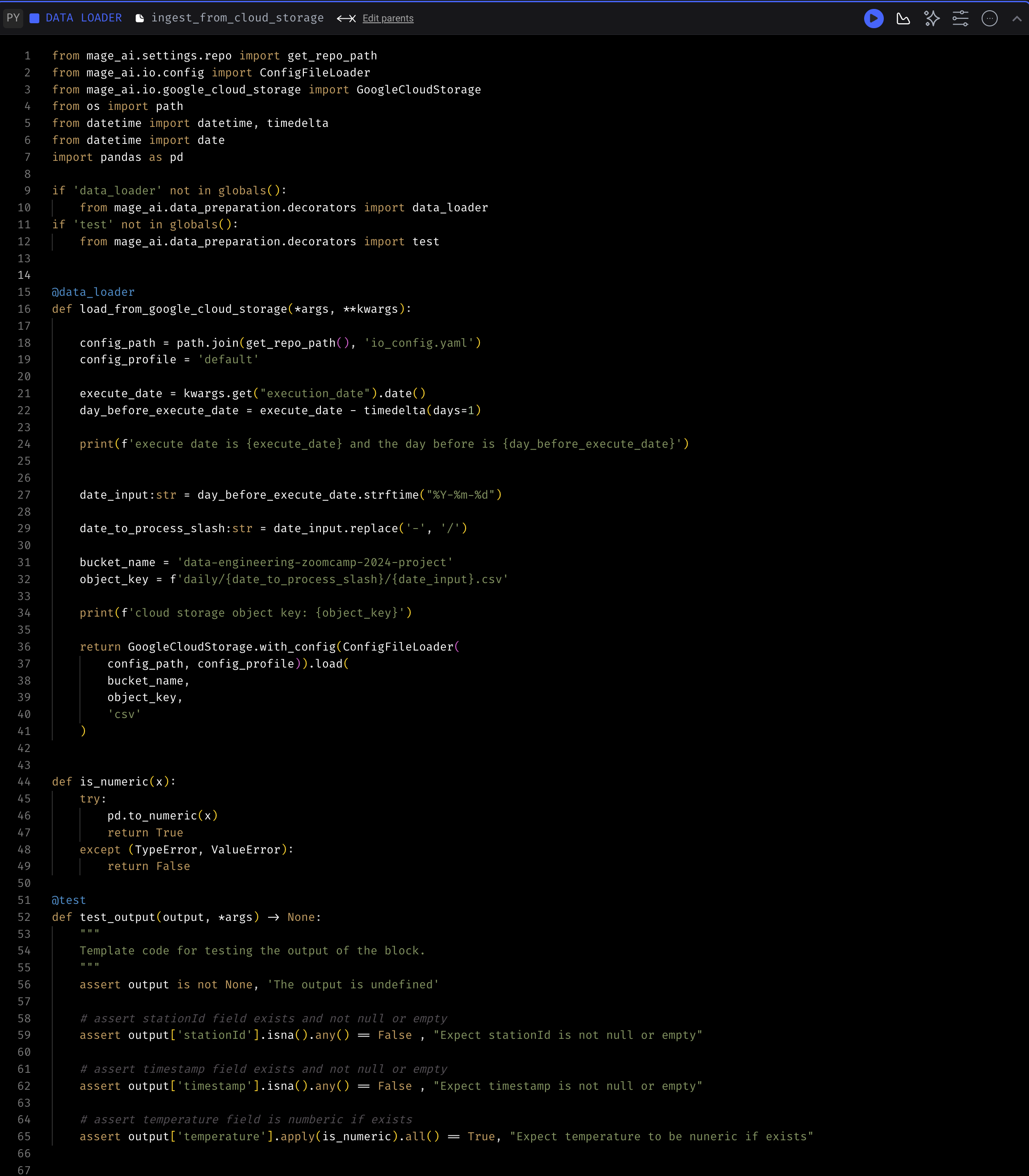
2. cleaning and add transform Transformer
See cleaning and add transform
Once the data is loaded into dataframe from the previous step, this transformer filters out rows which temperature field is null and adds 3 columns date, hour and minute using the value from timestamp column.
The transformed dataframe is then subject to the tests specified under @test block where we verify that the 3 new columns are non-null.
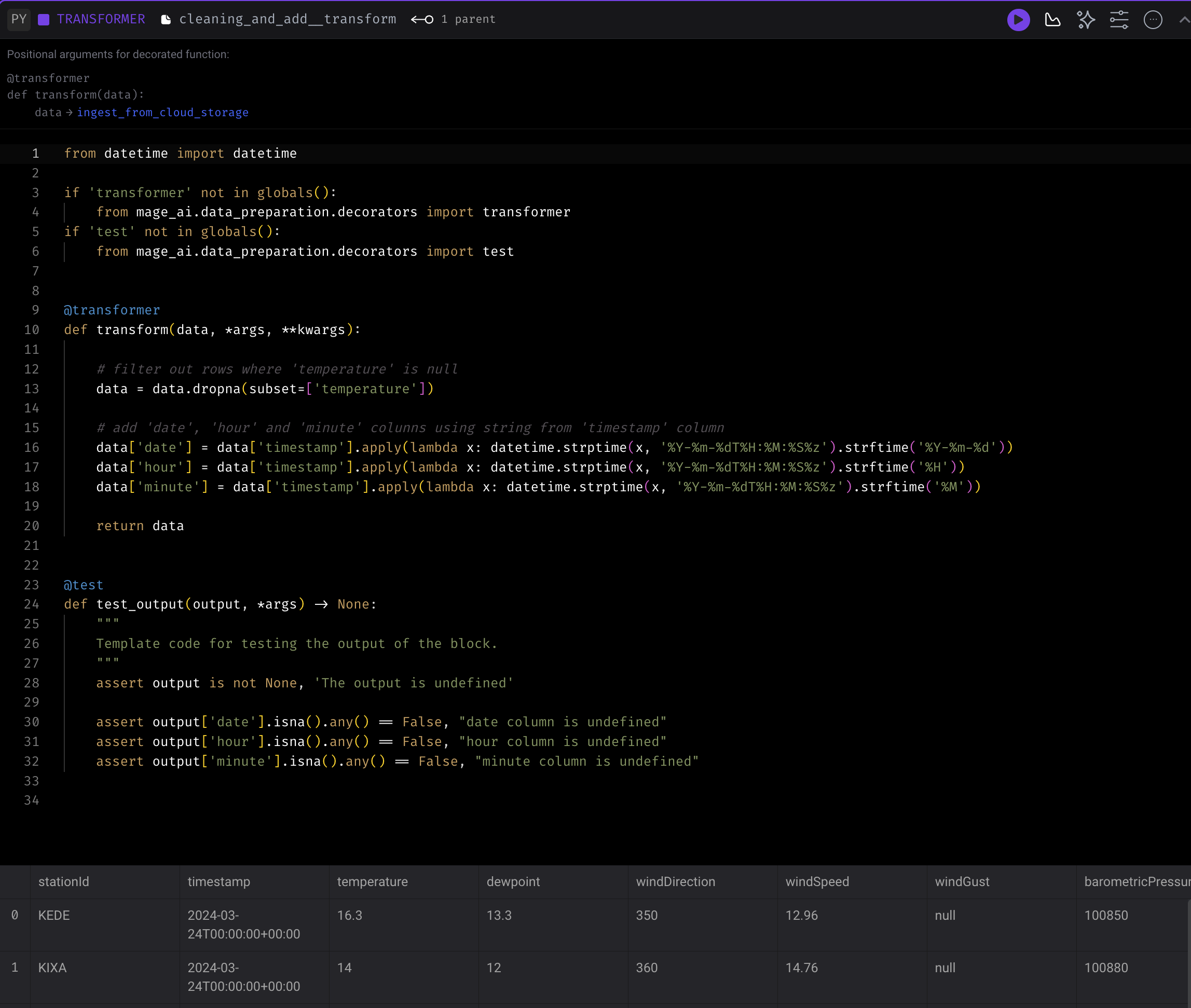
3. remove duplicates Transformer
The transformer is checking duplicate rows based on the combination of stationId, date, hour and minute columns and keeps the last record.
Under the @test block we verify that the output dataframe is non-null.
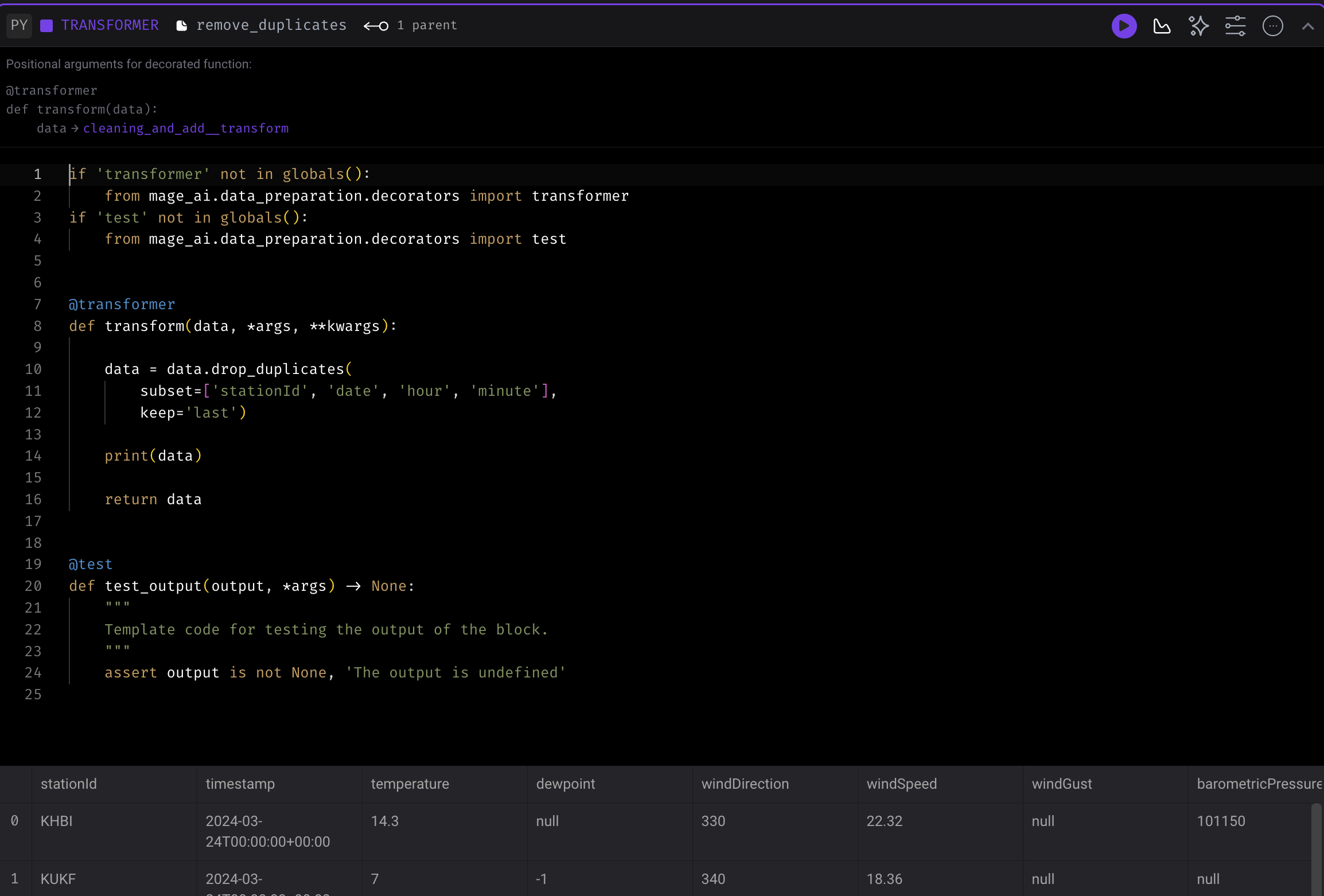
4. store to big query Data Exporter
This data exporter uploads the dataframe to BigQuery dataset called project_dataset and table weather_data.
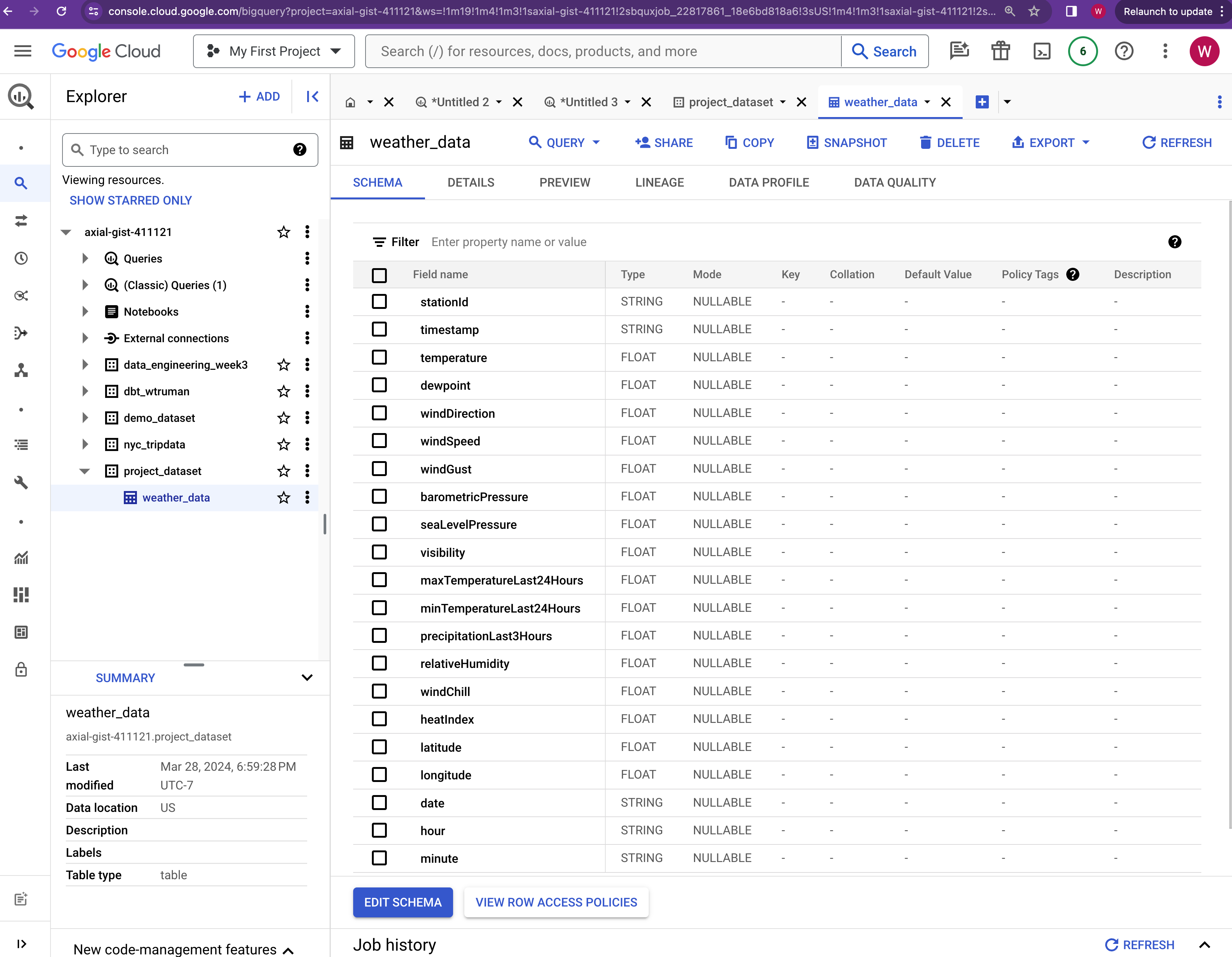
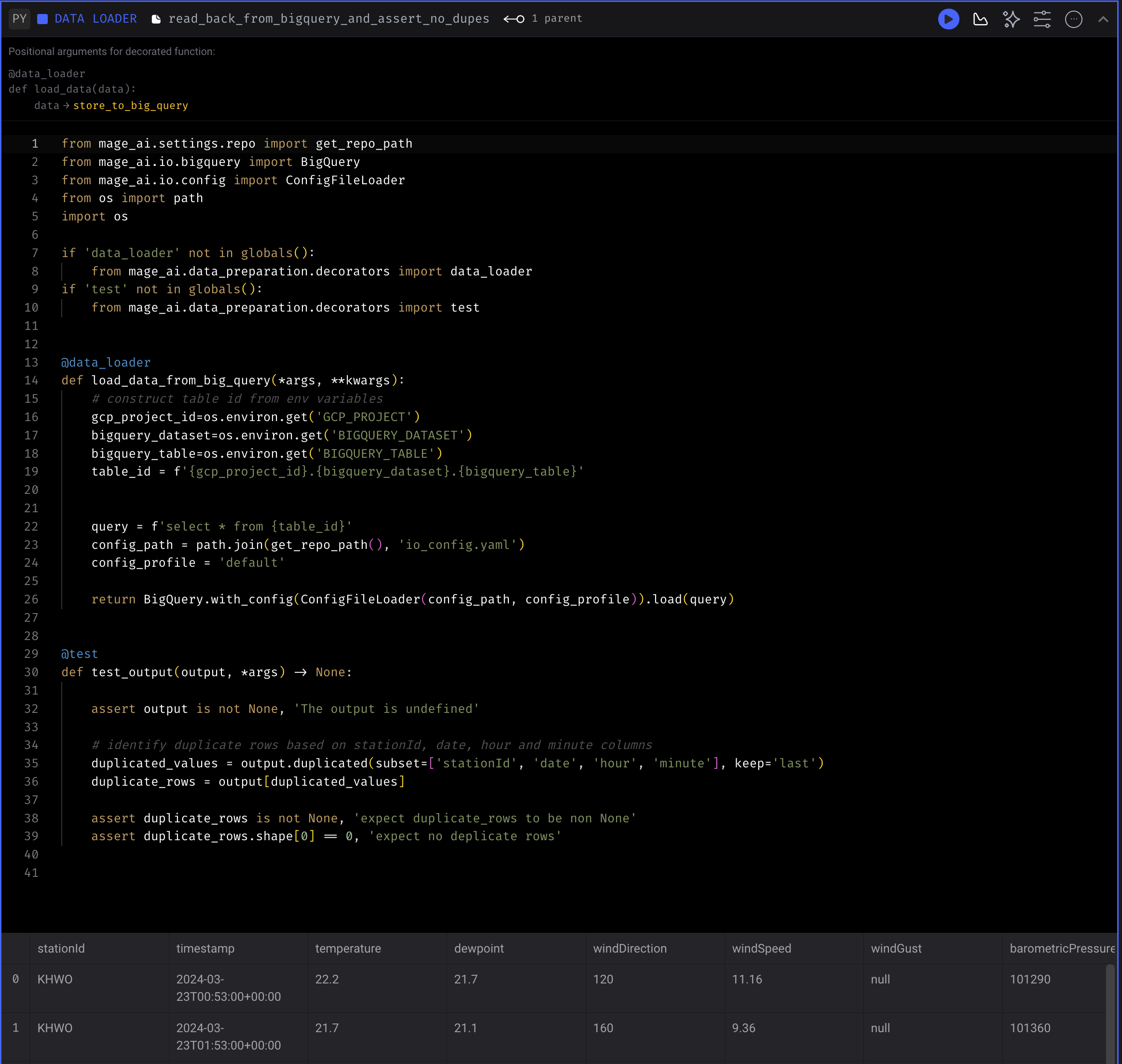
5. read back from bigquery and assert no dupes Data Loader
See quality check
This data loader performs quality check by reading data from BigQuery table and make sure there is no duplicate rows in the table based on the same unique criteria described in remove duplicates transformer.
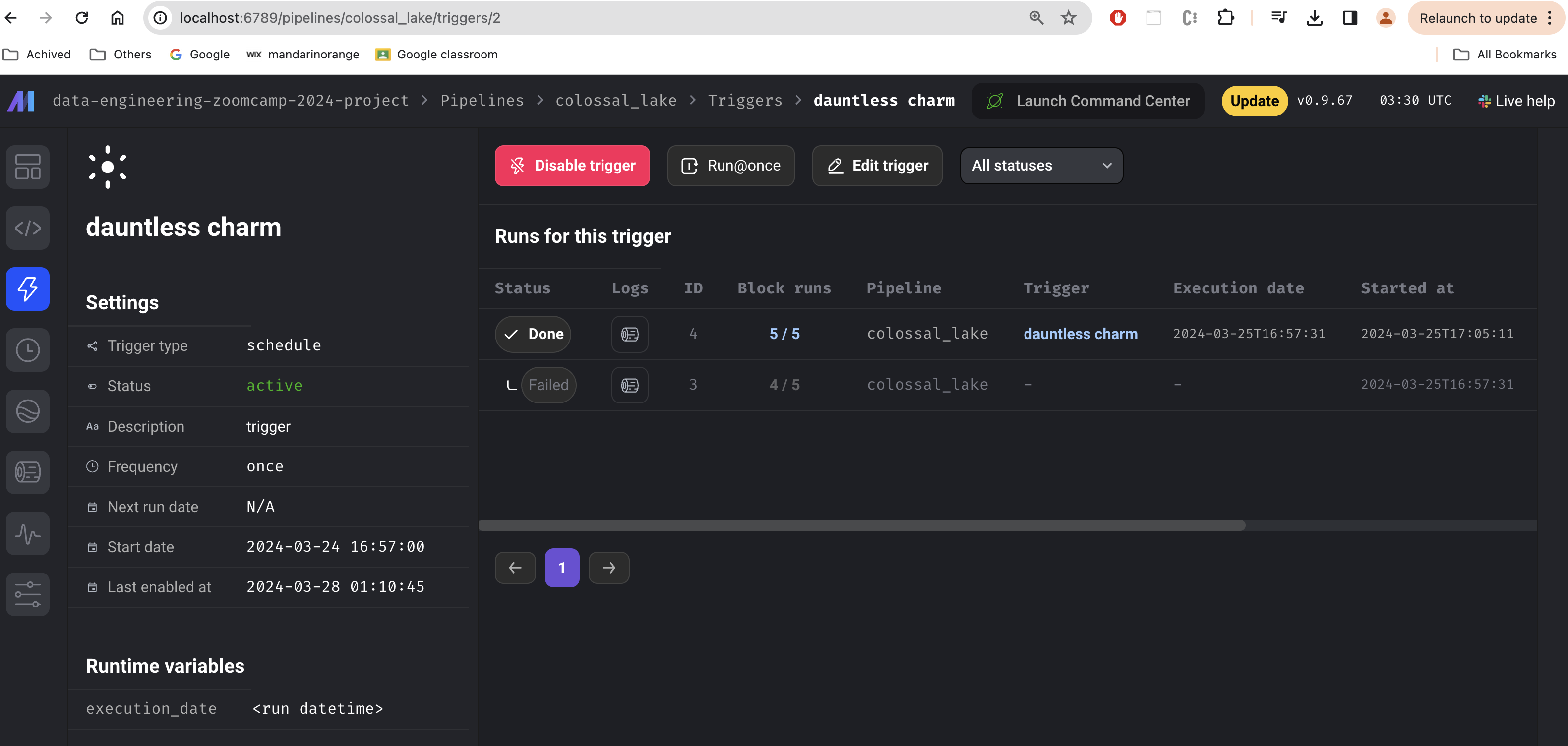
Mage Pipeline Trigger
A daily scheduled trigger is created to execute the pipeline. Trigger can also be triggered manually.
Backfill
See backfill for detail explanation of how this solution handles backfilling.